·密码学原理课程 —— Perfectly Secret Encryption
密码学原理专栏——香农完善保密理论、一次一密乱码本
Perfectly Secret Encryption
本章节的思维导图如下所示,

在本章节中我们主要介绍完善保密理论(Perfectly Secret Encryption)并且给出一些在往下章节中经常使用的检验密码方案安全性的实验交互模型。在描述这些模型时,我们需要使用到一些基础的概率论知识,并且还需要讨论一些用于该模型中随机算法。
Generating randomness
在密码学中,我们经常需要产生并使用一些随机数,这些随机数的概率分布影响着密码的安全性,一些随机性较差的随机数很有可能使得该密码方案被攻破,如何高效可靠的产生随机数是密码学中一个重要的问题。在讨论随机数时,我们应该想到一个问题,随机数是如何产生的呢?由于经典的算法输出的结果都是确定性的,计算机如何产生随机数始终困扰着我。当然了,在现实生活中我们可以通过一些物理事件去产生随机的结果,比如我们可以通过抛硬币来确定一个数的比特位,从而得以生成任意长度的随机数。
我们回到我们最先提出的那个问题,计算机是如何产生随机数的呢?在现代随机数生成的过程中,主要有以下两个步骤,
- 计算机维护着一个高熵值的数据池,这些数据可以来自于系统中断(比如时钟中断、I/O访问请求),一些特定的物理事件。值得注意的是不管这些高熵数据的来源是什么,它们都必须得满足一点:其数据必须是不可被预测的
- 计算机利用高熵值数据池中的数据去扩展出一系列近乎独立与无偏差的比特流。该步骤是必不可少的,因为高熵值数据不需要严格服从均匀分布,而我们生成的随机数为使其可以安全应用于密码学组件中,其必须是得满足均匀分布的。[1]
为了更好地理解[1]中所提到的步骤,我们借用教材中的例子(PG.24)去加以说明。
想象现在我们已经有了一个存储了大量高熵数据数据池,其中包含着有偏移比特序列。我们不妨假设其中 0 出现的概率为 $p$ 而 1 出现的概率为 $1-p$ (细心的读者可能会注意到按照我们这样的定义将会使得 0 与 1 出现的概率不是相互独立的,而实际上它们两者应该是相互独立的。这意味着上述假设在实践中并不是那么有效,并且我们需要做一些更加复杂的处理使得我们产生的随机数能够服从均匀分布) 在熵池中,我们有着数千比特,(比如 01001010100101101101110……),它们提供了较大的熵值。我们为了从中提取中服从均匀分布的随机数可以作如下处理,
我们将上述比特流中的比特两两相邻组合成为一组,如果我们看到的比特组合为 10 我们的随机数生成器就可以先输出一位 0,如果我们看到的比特组合为 01,那我们的随机数生成器就可以输出一位 1,如果我们看到其它的组合方式我们可以采取简单方式忽略这些特定的比特组合,这样我们便能够生成符合我们要求的随机数了。
分析上述例子所产生的随机数每一位比特的概率,当随机数某一位比特为1的概率为 $p*(1-p)$ 恰好等于该位置比特为0的概率。01 00 10 10 10 01 01 10 11 01 11 ——> 100011011
在密码学应用实践中,我们必须使用为密码学应用而设计的随机数生成器,避免使用不安全的随机数生成器作为密码学应用的组件。伪随机(与此相对的是我们先前提到的真随机)数生成器使用一些随机性算法来高效的生成随机数(mersenne twister),它们提供了一种高效生成随机数的方式,但在某些情况下它们却是不安全的,因此它们也经常成为CTF中相关题型的常客。我们在后续的章节中还会继续讨论有关随机数生成器的相关问题。
Definitions
在本节中,我们将会介绍完善保密的三种等价定义方式,并且给出基于实验交互证明密码方案安全性的模型,该模型在往后的学习过程中将会不断地出现,并且作为密码学证明中一种固定的范式,我们需要熟悉并且掌握这种证明密码方案安全性的思路与方式。为了章节的篇幅考虑,一些在证明中出现的notation我会在后续的举例中说明。
Perfect secrecy

用平常的语言来概括一下上述定义就是:当我们观察到密文 $c$ 时,我们无法从中获得任何有关于明文 $m$ 的任何信息,这句话对于任何 $c\in C,\space m\in M$ 都成立。注意到 $Pr[M=m|C=c]=Pr[M=m]$,在我们观察到 $c$ 的条件下明文 $m$ 的概率分布与其原有的概率分布相同,这也就是说当我们对明文做的加密操作并没有改变明文的概率分布,攻击者无法从这个加密中获得任何有助于其重新恢复明文的有用信息。
假设我们有两段消息,其要么是 $m=ab$,要么是 $m=ab$,现在我们取 $m=ab\space and \space c=XX$,我们很容易可以得到 $Pr[m=ab|c=XX]=0$ (在简单的移位密码Caesar Cipher情况下,明文 $ab$ 无法通过任何操作得到密文 $XX$),然而 $Pr[m=ab]=\frac{1}{2}$,这也就说明了移位密码不会是完善保密的。
- 下面我们给出完善保密的第二种等价定义,
$$ Pr[Enc_k(m)=c]=Pr[Enc_k(m')=c]\space (2.1) $$
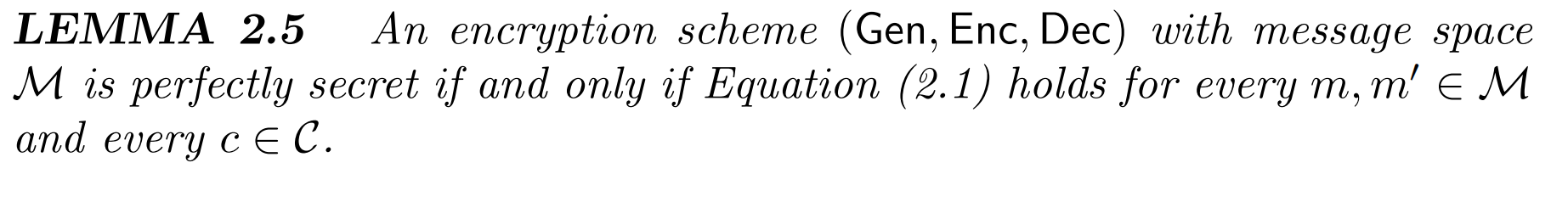
该等式说明一个密码方案它要是完善保密的,其密文的概率分布就不应该依赖于明文。换句话说,假设任意两条消息 $m,m'\in M$,$m$加密后得到的密文的概率分布应该与$m'$加密后得到的密文的概率分布相互独立。那么我们现在可以考虑一个问题:既然密文的概率分布和明文的概率分布相互独立,那么通过加密函数 $Enc$ 后,密文的概率分布应该与哪一个随机变量相关呢?
这个问题的答案也是显而易见的,密码方案的随机性是通过随机数引入的,这也就是说一个明文如何映射到一个密文上是由我们所采用的密码方案和所使用的密钥决定的。上述表述暗含了我们第三种完善保密等价表述的一些内容,即密文没有蕴含任何有关明文的信息,密文的概率分布与明文的概率分布相互独立,亦即我们无法区分出给定两条消息$m,m'$ 以及由这两者经过加密之后得到的密文 $c,c'$ 之间的对应关系。(我们无从得知 $c$ 是由 $m$ 加密得到的还是由 $m'$ 加密得到的)猜测 $c$ 是由 $m$ 加密产生或由 $m'$ 加密产生其概率都为 $\frac{1}{2}$,这也相当于在 $m$ 与 $m'$ 之中随机选择一个作为你给出的答案。
其与第一种定义表述等价的严格证明在教材(PG.28)中,有兴趣的同学可以自行参考教材。
- 最后我们给出完善保密的第三种等价定义,这也是我们在密码学原理这门课程中最常见地定义密码方案的一种方式——通过一种交互实验的模型
Perfect (adversarial) indistinguishability
设想有一攻击者 $A$,他可以指定任意的消息的明文 $m_1,m_2\in M$,接着 $Gen$ 生成一个随机密钥 $k$ 。我们从 $A$ 指定的两个明文之中均匀随机的挑选出一条明文 $m_b$,并使用密钥 $k$ 对明文 $m_b$ 进行加密。最终 $A$ 能够观察到加密后的密文,我们让 $A$ 去“猜测”(如果他有更好的办法的话也许不能够叫做猜测) 我们所加密的密文 $Enc_k(m_b)$ 对应的明文是 $m_1,m_2$ 中的哪一个。我们可以作如下定义,$A$ 在这次实验中成功当且仅当其猜对了密文所对应的明文。
在上述铺垫过后,我们可以对敌手不可区分性下一个定义,
An Encryption scheme is perfectly indistinguishable if no adversary $A$ can succceed with probability better than $\frac{1}{2}$. We stress that no limitations are placed on the computational power of $A$
上述定义告诉我们,一个加密方案若满足敌手不可区分性,那么也就意味着没有任何一个敌手 $A$ 能够使得上述实验成功的概率大于 $\frac{1}{2}$,并且我们并不需要限制敌手 $A$ 的计算能力。简单来说,攻击者 $A$ 在拿到我们加密过后的密文之后并不能从密文中有效的区分出其给定的明文的一丁点儿信息,他对输出结果的选择是真实地猜测(也就是在$m_0,m_1$中均匀随机二选一),它没有更好地办法(算法)使得其能够区分出该密文是由哪一个明文加密而来的,这也就是我们上述在其它完善保密的定义中一直强调的密文不泄露明文的任何信息。这样,我们便可以给出基于实验交互的模型。
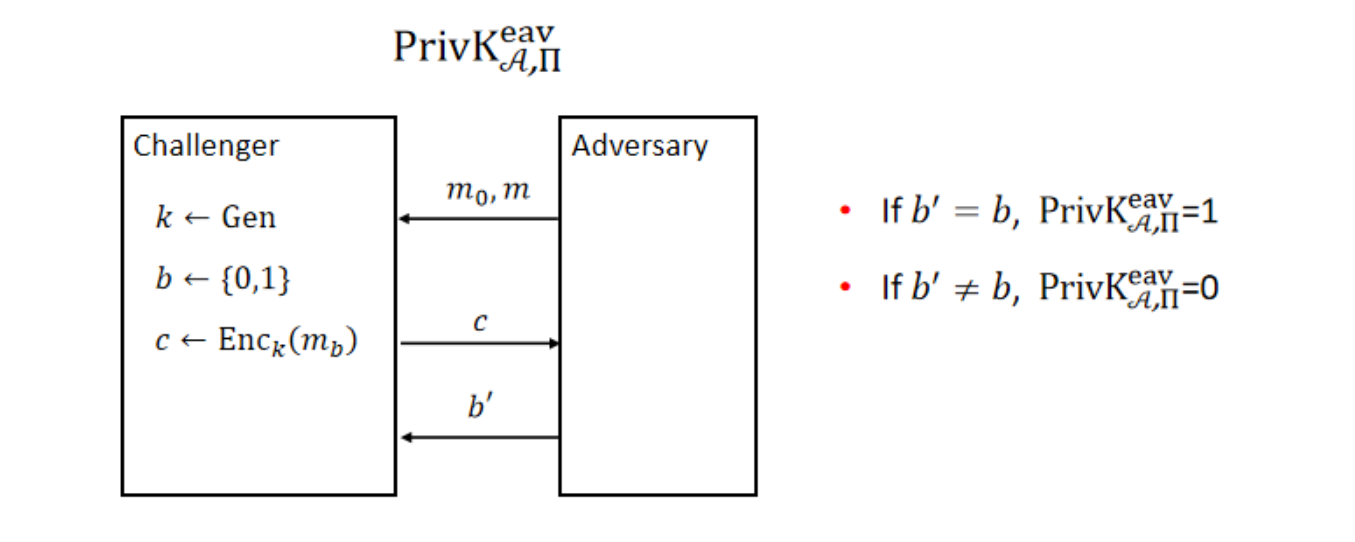
The adversarial indistinguishability experiment $PrivK^{eav}_{A,\pi}$ :
- The adversary $A$ outputs a pair of messages $m_0,m_1\in M$.
- A key $k$ is generated using $Gen$, and a uniform bit $b\in {0,1}$ is chosen. Ciphertext $c\gets Enk_k(m_b)$ is computed and given to $A$. We refer to $c$ as the challenge ciphertext.
- $A$ outputs a bit $b'$
- The output of the experiment is defined to be 1 if $b' =b$, and 0 otherwise. We write $PrivK^{eav}_{A,\pi}=1$ if the output of the experiment is and in this case we say that $A$ succeeds.
解释一下上述notations的含义,$PrivK$ 代表该Experiment是在Private-Key Encryption中的,$eav$ 描述了攻击者 $A$ 的能力为仅能够窃听信道,$A$ 指定了一个攻击者,$\pi$ 代表了具体所使用的Private-Key Encryption的scheme,亦即指定了 $Enc_k(m_b)$ 的具体形式以及相关的预操作。
实验交互框图如下所示,
经过上面的铺垫之后,我们能够给出完善保密的第三种等价定义,

教材(PG.30)中展示了使用第三种定义方式判断Vigenère cipher在某些参数设置下不是完美不可区分的相关证明,有兴趣的读者可以自行参考。
The One-Time Pad
在本节中,我们将会介绍一个 perfectly secret encryption scheme 的实例 —— One-Time Pad (一次一密乱码本)
在1917年,Vernam为他的完善保密加密方案申请了一项专利,现如今其加密方案即我们所熟知的 one-time pad. 在他提出该加密方案的那个年代还没有完善保密的概念更没有相关的证明。事实上过了25年之后,香农给出了完善保密的定义并且展示了一种满足完善保密定义的加密方案,即我们这里所说的One-Time Pad。
为了介绍 One-Time Pad 中 $Enc_k(·)$ 的具体实现,我们需要了解一下异或(XOR)及其相关性质,具体的资料可以参考维基百科,在此便不在赘述。
THEOREM 2.10 The one-time pad encryption scheme is perfectly secret.
下面我们来看一下 One-Time Pad Encryption Scheme 的具体构造,

有关该方案是完善保密的证明在教材的(PG.32)中有详细说明,关键证明为我们所提到的完善保密的第一种等价定义 $Pr[M=m|C=m]=Pr[M=m]$,通过全概率公式以及贝叶斯公式的转化我们可以很容易的将问题解决,关键是要注意到 $Pr[C=c|M=m]=2^{-l}$ ,这里的 $l$ 指的是密钥长度。在此强调在观察到一个确切的明文时我们对其经过加密后得到的特定密文的概率取决于加密方案本身。
一个很简单的例子,对于一个 $Enc_k(·)$,无论其输入是什么,我们都定义其输出为一个确定的 $c^{*}$ ,这样在提供加密方案的情况下我们很容易可以知道 $Pr[C=c^*|M=m]=1$
在一个这么简单的例子中,我们可以发现一个事实,即一个加密方案若是确定性的加密方案,其必定不可能是安全的,我们必须引入一些随机化到加密方案中以实现 $Pr[C=c|M=m]$ 为一个较小的概率(根据安全性参数去确定这个概率到底需要多小)
一次一密乱码本加密方案是完善保密的正确性建立在其密钥没有重复使用的前提之上,下面我们考虑一个密钥重用的例子。
考虑我们使用相同的密钥 $k$ 去加密两条消息 $m_1,m_2$ 根据一次一密加密方案,我们很容易的得到其加密后的密文 $c_1=m_1\oplus k,c_2=m_2\oplus k$,我们可以对 $c_1,c_2$ 进行异或来消去密钥 $k$ 的 mash,即 $c_1\oplus c_2 = m_1 \oplus m_2$ 通过该操作之后,我们可以恢复关于明文的信息,这显然不符合完善保密的定义。
这也告诉我们重复使用密钥可能是一个非常危险的举动,在相关密码应用的设计中应该时刻注意到这一点,避免使用相同的随机化参量。
有关 One-Time Pad Encryption Scheme 的历史趣闻可以在教材的(PG.33)中获取,有兴趣的读者可以自行了解。
Limitations of Perfect Secrecy
既然完善保密理论告诉我们满足完善保密定义的加密方案在不考虑敌手计算能力的情况下都是十分安全的,那么我们是不是就可以万事大吉,在应用实践中全面使用完善保密加密方案就行了呢?答案肯定是否定的,为了达到如此的安全性,其所付出的代价也是十分明显的,以至于无法在实践中大面积应用。在这节中,我们将阐述完善保密理论内在的缺陷,注意这缺陷并不是针对特定的加密方案,而是在完善保密其内有的特性。
具体来说,我们可以证明任何完善保密加密方案的密钥空间至少要与其明文空间一样大 $|K| = |M|$ ,如果所有的密钥都是相同的长度并且明文空间中的明文长度也固定的话,这意味着密钥至少要与明文一样长,在 One-Time pad 中达到了这种情况的最优值(明文长度等于密钥长度)。
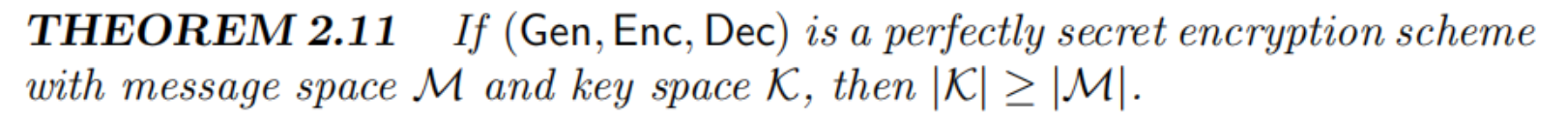
该定理相关的证明可以在教材中(PG.34)中找到,有兴趣的读者可以自行参考。
假设 $|K|<|M|$,去证明 $Pr[M=m|C=c]\neq Pr[M=m]$ 不符合完善保密定义
由于 $|K| < |M|$ ,这将导致某一确定的密文 $c^{*}$ 通过 $Dec_k(·)\space\forall\space k\in K$ 之后得到的集合 $M(c^{*})$ 有 $|M(c^{*})| <|K|$ ,也就意味着存在 $m'\in M$ 但是 $m'\notin M(c^{*})$ ,由此我们可以得到
$Pr[M=m'|C=c^{*}]=0\neq Pr[M=m']$,这样我们便可以证明 THEOREM 2.11
要想达到完善保密的安全性就必须使用至少与明文空间大小相同的密钥空间,任何试图说明其加密方案可以使用短密钥达到完善保密安全性的方案都是在耍流氓:)
使用完善保密加密方案去加密长消息在存储开销上显然是不经济的(我们需要一个与原文件至少一样大的密钥!!!),这种开销在网络带宽受限并且昂贵的情况下更是无法接受。比起绝对的安全,人们更想经济地实现安全(使用短密钥加密长消息并能够达到令人满意的安全性需求)
*Shannon’s Theorem
Shannon’s Theorem 提供了另一种判定该方案是否是完善保密的另一种表述,该表述的粗略描述如下:在特定的条件下,密钥生成算法 $Gen$ 必须随机均匀的从所有可能的密钥集合中(在密钥空间中)选取一个集合元素作为 $Key$ 。更进一步对于所有明文空间中的任意消息 $m$ 和所有密文空间中的密文 $c$ 都存在着一个由 $m$ 到 $c$ 独一无二的映射(由特定的密钥 $k$ 决定)在这里该定理的陈述基于 $|M|=|K|=|C|$ 的假设,满足这种假设的完善保密方案可以说是一种最优的方案,因为我们上述讨论过要是得方案满足完善保密必须有 $|K|\geq|M|$ 且 $|C|\geq|M|$

详细证明可参考教材(PG.35)
香农定理给出了一个能够使用简单的方式(不需要去计算概率)去判断一个加密方案是否满足完善保密的方式,不过要注意使用Shannon’s theorem的前提,即 $|M|=|K|=|C|$
在Shannon’s Theorem中我们还能了解到以下事实,对于任意一个明文消息 $m$ 其唯一映射到一个密文空间中的元素 $c$,具体的映射关系由 $k$ 与具体的加密方案所决定。并且在 (1) 中决定了 $k$ 的选取必须均匀随机,否则明文映射到密文上的概率分布就不是均匀分布了,而这就会破坏完善保密。